
CoLong Idea Studio开源项目详解
这篇文章围绕 CoLong Idea Studio 展开,介绍我在长篇 AI 创作方向上的整体探索,以及动态记忆优先、协同创意完善和章节生成闭环这些核心设计。
原文链接:https://blog.csdn.net/xyc_yyds/article/details/159169356
GitHub:https://github.com/HITSZ-DS/CoLong-Idea-Studio.git
线上平台:https://colong-idea-studio.cloud
一、为什么要做这个项目
如果只把 AI 写作理解成“输入一句 prompt,输出一段文本”,那它最多只是即时生成器,很难真正支持长篇创作、持续创作、多人协作和高一致性创作。
我做 CoLong Idea Studio 和 Write-Claw,本质上都在回答同一个问题:
AI 怎样从一次性文本生成工具,演进为一个能够持续思考、持续记忆、持续规划、持续观察、持续协作的长篇创作系统。
这两个项目的侧重点并不相同:
CoLong Idea Studio更偏方法论和系统引擎,强调动态记忆优先、协同创意完善、长篇章节一致性、可观测进度日志,以及从创意到正式生成的完整闭环。Write-Claw更偏运行时工作台和交互界面,强调把 AI 写作过程可视化、可打断、可修正、可编辑、可接管,让作者始终处在 loop 内部。
如果用一句话概括两者关系:
CoLong Idea Studio 更像“方法与引擎”,Write-Claw 更像“工作台与可视化运行时界面”。
二、这个项目到底想解决什么问题
长篇 AI 写作最难的不是“写不出来”,而是“写不稳”。
真正的问题主要集中在这些地方:
- 前后章节容易漂移,人物性格会变,设定会变,事实会冲突。
- 初始创意通常并不完整,用户给出的往往只是故事种子,而不是可直接执行的写作简报。
- 大部分系统只展示最终输出,不展示中间过程,用户很难知道模型为什么这样写。
- 一旦写偏,用户只能重来,缺少中途打断、修正、插入约束、检查记忆和查看阶段状态的能力。
- 很多工具把“记忆”做成静态知识库,但长篇创作真正需要的是动态生成、动态写回、动态检索、动态再注入。
所以我关注的问题不是“让模型多写点字”,而是:
- 如何在长篇、多章节、多轮交互场景下维持一致性。
- 如何在正式生成前把创意从模糊状态打磨到可执行状态。
- 如何让生成过程不再是黑盒,而是可见、可追踪、可干预。
- 如何把人物、世界观、情节线、事实约束、章节摘要这些信息变成真正支撑后续章节的动态记忆结构。
- 如何让系统同时具备研究表达价值和产品化价值。
三、项目定位
CoLong Idea Studio 是一个动态记忆优先的长篇创意协同与故事生成框架,面向长篇、分章、高一致性创作任务,强调:
- 协同创意完善
- 动态记忆驱动生成
- 过程可观测
它不是简单的“RAG + 写作”。
更核心的思想是:写作过程本身会不断产生新的结构化信息,而这些信息会反过来影响后续写作。
也就是说,系统不是“先准备知识,再开始写”,而是形成这样一个闭环:
- 用户提出初始创意。
- 系统通过协同创意 agent 把创意打磨成更稳定的写作简报。
- 系统生成全局大纲和章节大纲。
- 人物设定、世界设定、章节计划、章节摘要、事实卡片在生成过程中不断写回。
- 后续章节再根据这些动态生成的记忆检索上下文。
- 最终形成
planning -> writing -> retrieval -> storage -> reinjection的闭环。
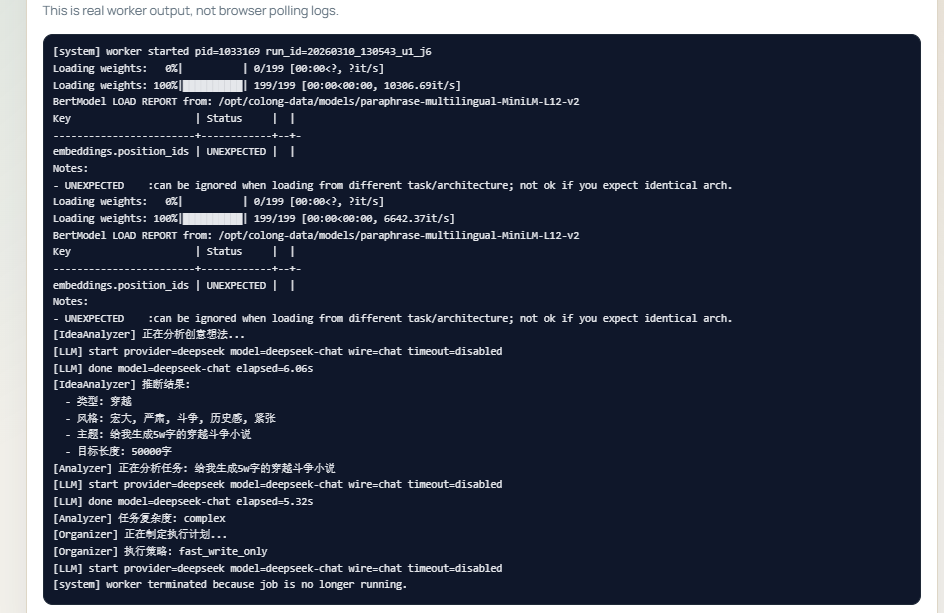
四、系统架构与工作流
从代码和文档可以看出,项目主要由这些层面构成:
agents/:负责创意协同、情节、人物、世界观、写作、检索等不同子任务。workflow/:负责分析、组织和执行整个任务流。rag/:负责动态记忆、向量存储、检索、一致性检查、实时编辑、转折点追踪。local_web_portal/:负责本地优先的 Web 交互入口、用户管理、任务管理和状态展示。runs/:保存每次生成的运行轨迹与产物。vector_db/与vector_db_tmp/:用于保存动态记忆、知识索引与临时向量数据库。
执行闭环大致如下:
Idea Analyzer先分析用户创意,推断主题、风格、体裁与建议长度。Analyzer分析任务复杂度和生成需求。AdaptiveOrganizer自动构建执行计划,估计章节数和每章目标长度。- 系统生成全局大纲,再进一步切分章节大纲。
- 基于全局大纲预先生成部分人物、世界观和检索辅助设定。
- 每章写作前,系统生成当前章节计划,并从动态记忆中拉取相关上下文。
WriterAgent根据章节大纲、历史摘要、事实卡片和相关设定生成正文。- 生成结果写回记忆系统,同时写入
progress.log。 - 后续章节继续基于动态记忆进行检索与再注入。
这个流程的价值在于:
- 不是一次性把所有信息塞进 prompt。
- 不是写完后再做总结。
- 而是每一章都在持续更新系统的内部世界模型。
五、核心技术亮点
1. 动态记忆优先,而不是静态知识优先
在 config.py 中,系统默认走 memory_only_mode,也就是默认关闭静态 RAG 和静态知识库,把重点放在动态记忆上。
对长篇创作来说,最有价值的上下文往往不是外部知识,而是系统自己在生成过程中不断沉淀下来的内部记忆。
项目中的 MemorySystem 会维护 memory_index.json,主要包含这些类型:
textsoutlinescharactersworld_settingsplot_pointsfact_cards
这意味着系统不是只记正文,而是在主动维护一个多类型、可分组、可检索的创作记忆空间。
2. 记忆不是单一桶,而是分类型组织
很多项目做记忆时只是简单存储文本 chunk,但这个项目把记忆显式拆成多种语义角色:
- 正文是
texts - 大纲与章节摘要是
outlines - 角色信息是
characters - 世界观是
world_settings - 情节点是
plot_points - 事实约束是
fact_cards
这种类型化组织很关键,因为长篇小说中不同信息承担的作用并不一样。
3. 固定注入 + 语义检索 + 类型分组的上下文构造方式
MemorySystem.get_relevant_context() 不是简单把向量检索结果一股脑塞给模型,而是拆成三层:
- 固定注入:滚动摘要、最近章节摘要、最近事实卡片。
- 语义检索:从动态记忆向量库召回最相关条目。
- 类型分组:按人物、世界观、大纲、情节点、事实卡片组织上下文。
这种方式比单纯的 top-k 检索更适合长篇写作,因为它兼顾了全局连续性、最近上下文连续性、当前章节相关性和信息类型的可解释性。
4. 协同创意不是表单,而是 agent 级多轮过程
系统默认认为“好的创意输入”本身也需要通过多轮协同加工获得,而不是假设用户第一次输入就足够成熟。
这解决了一个很现实的问题:很多长篇创作失败,不是模型不会写,而是故事一开始就没有被定义清楚。
5. 章节级大纲驱动,而不是整书一次性自由生成
CompositiveExecutor 会先生成全局大纲,再切分章节大纲,再为当前章节生成具体写作计划。
这样做的直接好处是:
- 故事节奏更稳定。
- 每章边界和任务更明确。
- 长度控制更容易。
- 后续回顾和调试更方便。
- 与动态记忆系统天然契合。
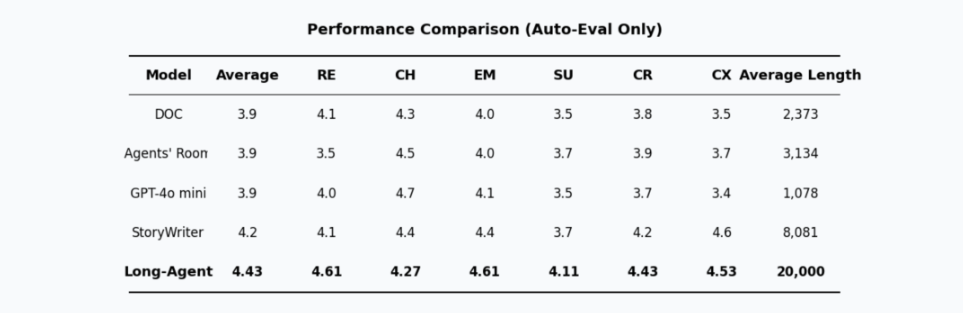
六、Research 方向成果
在 benchmark 方面,我们选择了 Story-Write THU 的 baseline,并取得了不错的结果。
后续也会继续在 Hugging Face 上推进协同式模型,重点放在用户交互方向。